Friday, July 29, 2005
Fuzzy Logic and Fuzzy SQL, or Richard's Big & Tall Shop
These explanations are based on my readings so far in Earl Cox's Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration
Fuzzy Logic, or Are you tall?
A more complete explanation can be found here, but here's a short version. Fuzzy Logic is a superset of Boolean Logic. In Boolean Logic, you're either in a set or not, and this can be represented by a membership function that returns either 0 or 1. In Fuzzy Logic, an item's membership in a set is measured in a continuous number from 0 to 1, determined by a membership function.
As an example, let's talk about "tall". A boolean membership function would be something like "if you're six feet or over, you're tall, else you're not". 0 or 1. A fuzzy membership function could be "if you're 5 feet or under, your tallness is 0. If you're 6 feet or over, your tallness is 1. From 5 feet to 6 feet it's a continuous slope". So, if someone is 5'9" their membership in the "tallness" set is .75.
In this logic system, a fuzzy AND of two numbers is the minimum of the numbers, a fuzzy OR is the maximum of the numbers, and a fuzzy NOT is 1 - a number. If you think of booleans as either 0 or 1, these operators are the same. Fuzzy is a superset of boolean.
Fuzzy SQL, or are you Tall and Heavy?
Let's say I'm opening a new chain of Big & Tall stores, and let's say I bought a database or broke into some insurer and have a huge list of names, addresses, heights and weights. I want to determine who in the database it would be worth my while to send a direct mailing. In regular SQL a query would look something like
select name, address from prospects where height => 74 and weight => 210;
That would give me a subset to work with, but what about someone who's 72 inches and 240? He's probably a pretty good prospect, but my boolean filtering would miss him. I could play with the cutoffs, but there would always be someone just outside, and if I move them too far I increase my chances of adding people who wouldn't be interested, and exclude the tall but not too heavy or heavy but not too tall.
Fuzzy SQL is a way of managing this problem. A Fuzzy SQL statement that we would use would look like
select name, address from prospects where height is tall and weight is heavy;
Looks kind of meaningless. What's "tall and heavy"? Well, first you start by computing individual membership numbers for the "tall" set and the "heavy" set using membership functions I wrote about above. Then with these individual numbers you compute what Cox calls a "Query Compatibility Index" (QCIX), which are different ways of combining the individual numbers. One way is the classic fuzzy AND, the minimum of the numbers. Another way is to average the numbers, perhaps with a weighted average, if for example I thought heavy was more important than tall. The Fuzzy SQL query should also return extra columns, such as the QCIX and perhaps the individual membership numbers calculated by the membership functions.
Sticking with a regular average would be OK for my direct mailing purposes. Tall and heavy would give a high QCIX, but also would very tall but not that heavy, and vice versa. So, the query is run and the rows sorted according to the QCIX, and we give a cutoff value for the QCIX below which rows are not returned. Print them envelopes, throw in a coupon and we're good to go.
The source code in the book is in Visual Basic, but what's the fun in that? What we really need is language that can add extra keywords such as the "is" and make it look like the rest of the language, that can take symbols like "tall" and "heavy" and associate them with membership functions....
Fuzzy Logic, or Are you tall?
A more complete explanation can be found here, but here's a short version. Fuzzy Logic is a superset of Boolean Logic. In Boolean Logic, you're either in a set or not, and this can be represented by a membership function that returns either 0 or 1. In Fuzzy Logic, an item's membership in a set is measured in a continuous number from 0 to 1, determined by a membership function.
As an example, let's talk about "tall". A boolean membership function would be something like "if you're six feet or over, you're tall, else you're not". 0 or 1. A fuzzy membership function could be "if you're 5 feet or under, your tallness is 0. If you're 6 feet or over, your tallness is 1. From 5 feet to 6 feet it's a continuous slope". So, if someone is 5'9" their membership in the "tallness" set is .75.
In this logic system, a fuzzy AND of two numbers is the minimum of the numbers, a fuzzy OR is the maximum of the numbers, and a fuzzy NOT is 1 - a number. If you think of booleans as either 0 or 1, these operators are the same. Fuzzy is a superset of boolean.
Fuzzy SQL, or are you Tall and Heavy?
Let's say I'm opening a new chain of Big & Tall stores, and let's say I bought a database or broke into some insurer and have a huge list of names, addresses, heights and weights. I want to determine who in the database it would be worth my while to send a direct mailing. In regular SQL a query would look something like
select name, address from prospects where height => 74 and weight => 210;
That would give me a subset to work with, but what about someone who's 72 inches and 240? He's probably a pretty good prospect, but my boolean filtering would miss him. I could play with the cutoffs, but there would always be someone just outside, and if I move them too far I increase my chances of adding people who wouldn't be interested, and exclude the tall but not too heavy or heavy but not too tall.
Fuzzy SQL is a way of managing this problem. A Fuzzy SQL statement that we would use would look like
select name, address from prospects where height is tall and weight is heavy;
Looks kind of meaningless. What's "tall and heavy"? Well, first you start by computing individual membership numbers for the "tall" set and the "heavy" set using membership functions I wrote about above. Then with these individual numbers you compute what Cox calls a "Query Compatibility Index" (QCIX), which are different ways of combining the individual numbers. One way is the classic fuzzy AND, the minimum of the numbers. Another way is to average the numbers, perhaps with a weighted average, if for example I thought heavy was more important than tall. The Fuzzy SQL query should also return extra columns, such as the QCIX and perhaps the individual membership numbers calculated by the membership functions.
Sticking with a regular average would be OK for my direct mailing purposes. Tall and heavy would give a high QCIX, but also would very tall but not that heavy, and vice versa. So, the query is run and the rows sorted according to the QCIX, and we give a cutoff value for the QCIX below which rows are not returned. Print them envelopes, throw in a coupon and we're good to go.
The source code in the book is in Visual Basic, but what's the fun in that? What we really need is language that can add extra keywords such as the "is" and make it look like the rest of the language, that can take symbols like "tall" and "heavy" and associate them with membership functions....
Monday, July 25, 2005
It's OK if you want to do this one
I've been working with ActiveMQ at work. In addition to being the Java Messaging System in Apache's Geronimo, it's also going to have open-source C libraries, and support from the financial community (See Here). What inspired me to write it that is also has REST API. This means that a fairly simple Lisp library could be whipped up to communicate with J2EE app servers, C applications, etc. I may get around to this eventually, but if someone else wants to have a crack at this that's OK with me.
Thursday, July 21, 2005
CLHS & CLTL in Compiled Help format
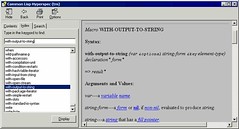
clhs-win
Originally uploaded by ralphrichardcook.
I've found where someone has put the CLHS and CLTL in WIndows Compiled Help format. What's so nice about this, at least on Windows, it that's much easier to search than navigating the links in a browser. It works great in Windows, pictured here, but the mac viewer doesn't do indexes or searches. I'll look for an X viewer and see if I can compile it on the mac.
The CHM files can be found here, scroll to the bottom for URL's.
Monday, July 18, 2005
Smug Lisp Weenies unite...or at least talk to each other
For a while I've been hearing about Ruby on Rails, and how Ruby's metaprogramming makes it possible to do it with so few lines of code. Well, we all know that Lisp invented metaprogramming, so I was thinking of working on a Lisp version of Rails. Then I see this. Someone who's worked on it for months, come up with a better version than I could, and is giving demos on it.
Time for Plan B.
I'm reading Earl Cox's "Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration". Upcoming chapters use something he calls "Fuzzy SQL" to model fuzzy sets, and genetic algorithms for tuning. I'm thinking of modifying or extending CLSQL to incorporate the Fuzzy SQL concepts, and look at John Koza's genetic programming for tuning in Lisp.
So, I'm asking, IS ANYONE ELSE DOING THIS? Am I going to start working on this, only to find a blog entry one day where someone's been working on this for months, come up with a better version than I could, and is giving demos on it?
If so, I'd appreciate it if you'd drop a comment here.
Time for Plan B.
I'm reading Earl Cox's "Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration". Upcoming chapters use something he calls "Fuzzy SQL" to model fuzzy sets, and genetic algorithms for tuning. I'm thinking of modifying or extending CLSQL to incorporate the Fuzzy SQL concepts, and look at John Koza's genetic programming for tuning in Lisp.
So, I'm asking, IS ANYONE ELSE DOING THIS? Am I going to start working on this, only to find a blog entry one day where someone's been working on this for months, come up with a better version than I could, and is giving demos on it?
If so, I'd appreciate it if you'd drop a comment here.
I think Pesty is a Lisp programmer

Optimization conundrums
I've been programming professionally for 20 years, and programming Java professionally for about five. Something I think I have in Java is a good feel for optimization and performance, at least on the micro level. What code is going to cause a lot of object creation, what choice of libraries is the best for a certain set of circumstances, etc.
Let's say I don't have that in Lisp yet. I worked on a benchmark for the Computer Language Shootout, and my best optimizations with declarations weren't doing so well. I asked for help on Usenet, Nicolas Neuss had a look, and, well, I'll just show you.
Here's my code (testrrc package) and Nicolas' (testnn package) combined for one of the routines.
This is compiled and run in CMUCL on my 1 Ghz iBook.
(proclaim '(optimize (speed 3) (safety 0) (debug 0) (compilation-speed 0) (space 0)))
(defpackage :testrrc)
(in-package :testrrc)
(defconstant IM 139968)
(defconstant IA 3877)
(defconstant IC 29573)
(defparameter THE_LAST 42)
(declaim (inline gen_random))
(declaim (inline gen_random))
(defun gen_random (max)
(declare (type (signed-byte 32) IM IA IC THE_LAST))
(declare (double-float max))
(setq THE_LAST (mod (+ (* THE_LAST IA) IC) IM))
(/ (* max THE_LAST) IM))
(defpackage :testnn)
(in-package :testnn)
(defconstant IM 139968)
(defconstant IA 3877)
(defconstant IC 29573)
(defparameter THE_LAST 42)
(declaim (inline gen_random))
(defun gen_random (max)
(declare (type (unsigned-byte 30) IM IA IC THE_LAST))
(declare (double-float max))
(setq THE_LAST (mod
(+ (the (unsigned-byte 31) (* THE_LAST IA)) IC) IM))
(/ (* max THE_LAST) IM))
(in-package :common-lisp-user)
(defun main ()
(time (dotimes (i 7500000) (testrrc::gen_random 1.0d0)))
(Time (dotimes (i 7500000) (testnn::gen_random 1.0d0))))
And here's the results.
; Evaluation took:
; 1.45 seconds of real time
; 1.142364 seconds of user run time
; 0.025509 seconds of system run time
; 1,529,475,015 CPU cycles
; 0 page faults and
; 5,127,264 bytes consed.
;
; Evaluation took:
; 0.28 seconds of real time
; 0.133931 seconds of user run time
; 6.7e-4 seconds of system run time
; 294,265,464 CPU cycles
; 0 page faults and
; 0 bytes consed.
Not only does that small change make it 5 times faster, but I have no idea why my version needs to cons 5 MEGS of bytes, and Nicolas' conses ZERO bytes. Anyone care to explain that one to me?
Let's say I don't have that in Lisp yet. I worked on a benchmark for the Computer Language Shootout, and my best optimizations with declarations weren't doing so well. I asked for help on Usenet, Nicolas Neuss had a look, and, well, I'll just show you.
Here's my code (testrrc package) and Nicolas' (testnn package) combined for one of the routines.
This is compiled and run in CMUCL on my 1 Ghz iBook.
(proclaim '(optimize (speed 3) (safety 0) (debug 0) (compilation-speed 0) (space 0)))
(defpackage :testrrc)
(in-package :testrrc)
(defconstant IM 139968)
(defconstant IA 3877)
(defconstant IC 29573)
(defparameter THE_LAST 42)
(declaim (inline gen_random))
(declaim (inline gen_random))
(defun gen_random (max)
(declare (type (signed-byte 32) IM IA IC THE_LAST))
(declare (double-float max))
(setq THE_LAST (mod (+ (* THE_LAST IA) IC) IM))
(/ (* max THE_LAST) IM))
(defpackage :testnn)
(in-package :testnn)
(defconstant IM 139968)
(defconstant IA 3877)
(defconstant IC 29573)
(defparameter THE_LAST 42)
(declaim (inline gen_random))
(defun gen_random (max)
(declare (type (unsigned-byte 30) IM IA IC THE_LAST))
(declare (double-float max))
(setq THE_LAST (mod
(+ (the (unsigned-byte 31) (* THE_LAST IA)) IC) IM))
(/ (* max THE_LAST) IM))
(in-package :common-lisp-user)
(defun main ()
(time (dotimes (i 7500000) (testrrc::gen_random 1.0d0)))
(Time (dotimes (i 7500000) (testnn::gen_random 1.0d0))))
And here's the results.
; Evaluation took:
; 1.45 seconds of real time
; 1.142364 seconds of user run time
; 0.025509 seconds of system run time
; 1,529,475,015 CPU cycles
; 0 page faults and
; 5,127,264 bytes consed.
;
; Evaluation took:
; 0.28 seconds of real time
; 0.133931 seconds of user run time
; 6.7e-4 seconds of system run time
; 294,265,464 CPU cycles
; 0 page faults and
; 0 bytes consed.
Not only does that small change make it 5 times faster, but I have no idea why my version needs to cons 5 MEGS of bytes, and Nicolas' conses ZERO bytes. Anyone care to explain that one to me?
![]()