Thursday, September 27, 2007
'Programming Collective Intelligence' in Common Lisp, Chapter 3 - Hierarchical Clusters
I have Common Lisp code for Chapter 3 up to Hierarchical Clusters. It's longer and not that interesting, so I'll just put up a link to the code. Once again, map and reduce are taking the place of list comprehensions, but other than that it's not particularly Lispy, no macrology or anything. Maybe next time.
Last time's tangent was a shortcut to hash syntax. This time I'm not happy with deleting items out of the middle of adjustable arrays. The code puts items on the end of an array and deletes them out of the middle, from a particular position.
In Python it's
What I have is
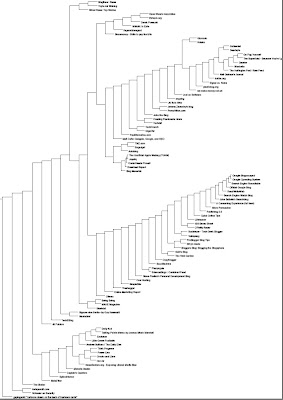
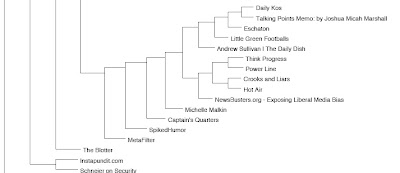
Instead of PCI's use of the Python Imaging Library or some Lisp equivalent, I used cl-pdf, which was easy to use to make the simple graphs, lines and text. This is the full hierarchical cluster, then a zoom view.
Last time's tangent was a shortcut to hash syntax. This time I'm not happy with deleting items out of the middle of adjustable arrays. The code puts items on the end of an array and deletes them out of the middle, from a particular position.
In Python it's
del clust[lowestpair[0]]What I have is
(defun truep (x) (declare (ignore x)) t)
(setf clust (delete-if #'truep clust :start (car lowestpair) :end (1+ (car lowestpair))))
Instead of PCI's use of the Python Imaging Library or some Lisp equivalent, I used cl-pdf, which was easy to use to make the simple graphs, lines and text. This is the full hierarchical cluster, then a zoom view.


# posted by Richard Cook @ 6:57 PM 
Comments:
<< Home
You can get rid of truep with constantly (one of my favorite "wow! that's neat..." moments in Lisp was discovering constantly):
(setf clust (delete-if (constantly t) clust :start (car lowestpair) :end (1+ (car lowestpair))))
(setf clust (delete-if (constantly t) clust :start (car lowestpair) :end (1+ (car lowestpair))))
# posted by  : 8:23 AM
: 8:23 AM
: 8:23 AM
Why do you use vectors for this task?
Lists seem far more natual.
I re-did the code as I would have written it (factoring out the memoisation of the distance function and the finding of the best pair to make things easier to understand), if you use lists and just remember the best elements, a simple delete (or rather two, unless you want to do delete-if (lambda (x) (member x lowestpair) ) -- see http://paste.lisp.org/display/48528
Lists seem far more natual.
I re-did the code as I would have written it (factoring out the memoisation of the distance function and the finding of the best pair to make things easier to understand), if you use lists and just remember the best elements, a simple delete (or rather two, unless you want to do delete-if (lambda (x) (member x lowestpair) ) -- see http://paste.lisp.org/display/48528
# posted by : 6:00 AM
: 6:00 AM
Well, that's annoying.
I used the vector version because I thought it would be faster, that deleting out of the middle of extendable vectors would be close to O(1) time vs. lists at O(n) time. Of course, I ran times on both versions and "Anonymous"'s list version is TWICE as fast as mine, and conses HALF as much as mine.
I'm going to go back and have a closer look at the code, and probably make a whole blog entry about it.
I used the vector version because I thought it would be faster, that deleting out of the middle of extendable vectors would be close to O(1) time vs. lists at O(n) time. Of course, I ran times on both versions and "Anonymous"'s list version is TWICE as fast as mine, and conses HALF as much as mine.
I'm going to go back and have a closer look at the code, and probably make a whole blog entry about it.

Now I'm more confused than annoyed.
I looked again at the code from paste.lisp.org, and noticed the defclass surrounded by the let. I didn't copy that part into my tests, and wanted to run multiple tests, so I changed the list version to also set the initial counter to -1 and decrement in the code and include the :id when making instances. Rerunning the tests now have both versions almost identical in timing.
I also drew the dendogram for the list version and it looks very different from the vector version, and the vector version resembles the version from the book. I'll need to get the Python code and use it on the same data to see what's up. (The author hasn't posted it yet.)
I looked again at the code from paste.lisp.org, and noticed the defclass surrounded by the let. I didn't copy that part into my tests, and wanted to run multiple tests, so I changed the list version to also set the initial counter to -1 and decrement in the code and include the :id when making instances. Rerunning the tests now have both versions almost identical in timing.
I also drew the dendogram for the list version and it looks very different from the vector version, and the vector version resembles the version from the book. I'll need to get the Python code and use it on the same data to see what's up. (The author hasn't posted it yet.)
Ah, sorry about that change. I had already forgotten about it. So, my code was faster because it did fewer distance calculaltions (all new nodes had id nil).
I guess the overall speed is then determined by the actual distance calculations and I made no change there.
As I don't have the data files I ran no tests -- I guess there is some bug in my code then as I thought it mimicked your logic enough that it should come up with the same results -- or does you code push new nodes at the end and mine at the front, so that equal distances would result in picking different pairs?
(Also apologies about the first anon post -- I didn't see the middle option to put a name to my comments.)
I guess the overall speed is then determined by the actual distance calculations and I made no change there.
As I don't have the data files I ran no tests -- I guess there is some bug in my code then as I thought it mimicked your logic enough that it should come up with the same results -- or does you code push new nodes at the end and mine at the front, so that equal distances would result in picking different pairs?
(Also apologies about the first anon post -- I didn't see the middle option to put a name to my comments.)
# posted by : 2:28 PM
: 2:28 PM
I use vector-push-extend, to mimic the Python code which also pushes on the end.
For some reason the author of the book hasn't made any of the test data "public", in other words put links on the Web, just in print in the book, so I'm respecting that.
For some reason the author of the book hasn't made any of the test data "public", in other words put links on the Web, just in print in the book, so I'm respecting that.
There is indeed a bug in my code -- in the routine to find the best pair. Replace the "and first = (car first-list)" with "for first = (car first-list)".
You still won't get an identical output because the order of left/right branches is different; structually the results are the same though.
I'll add another comment to my lisp paste how to fix the order, so that the results are the same.
You still won't get an identical output because the order of left/right branches is different; structually the results are the same though.
I'll add another comment to my lisp paste how to fix the order, so that the results are the same.
# posted by : 3:46 AM
: 3:46 AM
Code to fix the structural differences posted as http://paste.lisp.org/display/48528#2
Of course you could just add the new cluster node at the end -- e.g. replace "(push newcluster clust)" with "(setf clust (nreverse (cons newcluster (nreverse clust))))" -- then you won't need that hack/fix.
Post a Comment
Of course you could just add the new cluster node at the end -- e.g. replace "(push newcluster clust)" with "(setf clust (nreverse (cons newcluster (nreverse clust))))" -- then you won't need that hack/fix.
# posted by : 3:56 AM
: 3:56 AM << Home
![]()